प्रस्तावना:
प्रत्येक भाषा
के शब्द-वर्गों के भिन्न प्रकार के शब्दों को प्रणाली को समझाने के लिए कुछ
निश्चित टैग निर्धारित किए जाते हैं, जिससे कि उन शब्दों के इनपुट देने पर उनका
उचित एवं स्पष्ट परिणाम या आउटपुट(Output) प्राप्त किया जा सके। जैसे- हिंदी के
व्यक्तिवाचक संज्ञा के लिए ‘NNP’ जातिवाचक संज्ञा के लिए ‘NN’ सर्वनाम ‘PR’ मुख्य
क्रिया ‘VM’ एवं संयोजक ‘CC’ आदि के लिए टैग निर्धारित किए गए हैं। शब्द-भेद टैगिंग (Parts of Speech Tagging) से संबंधित कुछ अन्य छोटी-छोटी प्रक्रियाएं भी होती हैं जो निम्न हैं- नाम पद
चिह्नन, मुद्रा चिह्नन, दिनांक पद चिह्नन, पदबंध चिन्हन आदि।
टैगर के माध्यम से दिए गए इनपुट पाठ का दो भाषिक इकाइयों के बीच में खाली
स्थान या संभावित विराम के आधार पर शाब्दिक इकाइयों को अलग-अलग किया जाता है। इसका
विस्तृत विवरण आगे किया जा रहा है।
शब्दभेद(POS) टैगिंग:- टैगिंग का आरंभ सर्वप्रथम कार्पस टैगिंग से हुआ। पेंसिलवेनिया विश्वविद्यालय द्वारा ‘Penn Tree Bank’ के निर्माण हेतु प्रथम टैग सेट का विकास किया गया था जो इस प्रकार है-
Number Tag Description 1. CC Coordinating
conjunction 2. CD Cardinal
number 3. DT Determiner 4. EX Existential there 5. FW Foreign
word 6. IN Preposition
or subordinating conjunction 7. JJ Adjective 8. JJR Adjective,
comparative 9. JJS Adjective,
superlative 10. LS List
item marker 11. MD Modal 12. NN Noun,
singular or mass 13. NNS Noun,
plural 14. NNP Proper
noun, singular 15. NNPS Proper
noun, plural 16. PDT Predeterminer 17. POS Possessive
ending 18. PRP Personal
pronoun 19. PRP$ Possessive
pronoun 20. RB Adverb 21. RBR Adverb,
comparative 22. RBS Adverb,
superlative 23. RP Particle 24. SYM Symbol 25. TO to 26. UH Interjection 27. VB Verb,
base form 28. VBD Verb,
past tense 29. VBG Verb,
gerund or present participle 30. VBN Verb,
past participle 31. VBP Verb,
non-3rd person singular present 32. VBZ Verb,
3rd person singular present 33. WDT Wh-determiner 34. WP Wh-pronoun 35. WP$ Possessive
wh-pronoun 36. WRB Wh-adverb
शब्दों के साथ उनके
शब्दवर्ग आदि संबंधी सूचनाएं जोड़ने की प्रक्रिया टैगिंग है। आरंभ में केवल शब्दभेद
संबधी सूचनाएं ही जोड़ी जाती थीं, इस कारण इसे शब्दभेद टैगिंग कहा जाता था। प्रत्येक
भाषा में कुछ वर्ग समान होते हैं। अतः उनके टैग एक ही होने चाहिए किंतु भाषा विशेष
में पाये जाने वाले शब्दवर्गों के लिए स्वतंत्र टैग बनाये जा सकते हैं। हिंदी के
लिए IIT हैदराबाद और CIIL मैसूर द्वारा टैगसेट बनाये गए हैं। एक सामान्य हिंदी
टैगसेट इस प्रकार हो सकता है-
|
टैग |
शब्दवर्ग नाम |
हिंदी नाम |
उदाहरण |
|
NNP |
Proper noun |
व्यक्तिवाचक संज्ञा |
राम, मोहन |
|
NN |
Common noun |
जातिवाचक संज्ञा |
लड़का, छाता |
|
PR |
Pronoun |
सर्वनाम |
वह, तुम |
|
DT |
Determiner |
निर्धारक |
यह, वह |
|
VM |
Verb Main |
मुख्य क्रिया |
जाना, खाता |
|
JJ |
Adjective |
विशेषण |
सुंदर, बुरा |
|
RB |
Adverb |
क्रियाविशेषण |
तेज, धीमा |
|
QW |
Question word |
प्रश्नवाचक शब्द |
क्या, कौन |
|
UH |
Interjection |
विस्मयादिबोधक |
ओह, आह |
|
PP |
Postposition |
परसर्ग |
ने, को |
|
PT |
Particle |
निपात |
ही, भी |
|
NW |
Negation word |
नकारात्मक शब्द |
न, नहीं |
|
DE |
Date entity |
दिनांक पद |
20/2/2014, 20 फर. 2014 |
|
NM |
Number |
संख्या |
01, 23785 |
|
CR |
Currency |
मुद्रा |
$ |
|
TE |
Time entity |
समय पद |
12:13, 01:23 PM |
|
PM |
Punctuation mark |
विराम चिह्न |
; ‘ |
|
LS |
Listing |
सूचीकरण |
1. 2. |
|
CC |
Conjunction |
संयोजक |
और, किंतु |
|
PW |
Postpositional word |
परसर्गीय शब्द |
बाद, पहले |
|
VAX |
Verb Auxiliary |
सहायक क्रिया |
है, था |
|
VAS |
Verb Aspectual |
पक्षात्मक क्रिया |
रहा, चुका |
|
VEX |
Verb Explicator |
रंजक क्रिया |
चल दिया, कर बैठा |
|
CH |
character |
वर्ण |
अ, क |
|
PRP |
Reflexive Pronoun |
स्ववाची सर्वनाम |
अपना, खुद |
|
SFW |
Suffix Word |
प्रत्ययात्मक शब्द |
वाला, कर |
|
CW |
Compound Word |
सामासिक शब्द |
माता-पिता, रूप-निर्माण |
|
DW |
Duplicative Word |
द्विरुक्त शब्द |
पहला-पहला, चलते-चलते |
किसी पाठ की टैगिंग में पाठ में आए हुए शब्दों के साथ उनके टैग कई प्रकार से जोड़े जा सकते हैं: जैसे-
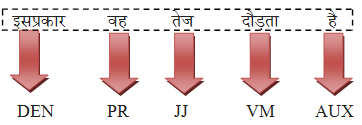
इस प्रकार टैग
संबंधी सूचनाएं सामान्य पाठ की तरह भी हो सकती है और प्रत्येक शब्द के साथ अलग-अलग
भी दी जा सकती हैं। जैसे-
ü इसप्रकार
/DEN/
ü वह
/PR/
ü तेज
/JJ/
ü दौड़ता
/VM/
ü है
/AUX/
जब किसी पाठ
का इनपुट(Input) दिया जाता है, तो जो सामग्री आउटपुट(Output) के रूप में प्राप्त
होती है। उसका वाक् चिह्नन हो जाने के बाद पाठ इनपुट का दो भाषिक इकाइयों के बीच
में आने वाले खाली स्थान और वाक् इनपुट में वास्तविक या संभावित विराम के आधार पर
शाब्दिक इकाइयों को अलग-अलग किया जाता है और उनकी शब्द-भेद टैगिंग की जाती है। POS
टैगिंग के आवश्यकतानुसार रूपवैज्ञानिक विश्लेषण का भी प्रयोग किया जाता है। यह
मुख्यतः दो प्रकार का होता है- रूपसाधक एवं व्युत्पादक। जैसे- ‘घोड़ा’ हिंदी भाषा
का एककोशीय शब्द है अतः इसे ‘मूल शब्द’ माना जाएगा। वाक्य में प्रयोग के आधार पर
इसके चार व्याकरणिक रुप प्राप्त होते हैं।
o घोड़ा जा रहा है: (एकवचन, प्रत्यक्ष रुप)
o घोड़े को जाने दो: (एकवचन, परसर्गीय, तिर्यक रूप)
o घोड़े जा रहे हैं: (बहुवचन, प्रत्यक्ष रूप)
o घोड़ों को जाने दो: (बहुवचन, परसर्गीय, तिर्यक
रूप)
रूपवैज्ञानिक
विश्लेषण प्रक्रिया को संपन्न करने वाली प्रणाली का नाम रूपवैज्ञानिक विश्लेषक है।
यह प्रणाली ‘घोड़ा’ के इन चारों रूपों का विश्लेषण कर ‘मूल शब्द’ घोड़ा से मैप
करेगा। जिससे कि इस शब्द की शब्द-भेद टैगिंग ‘जातिवाचक संज्ञा’ के रूप में की जा
सकेगी। रूप विश्लेषक प्रणाली में रूपविश्लेषण नियम एवं डेटाबेस(database) मुख्य
होते हैं। इसी प्रकार विभिन्न नियमों और डेटाबेस की सहायता से पाठ में आये सभी
शब्दों की शब्द-भेद टैगिंग की जाती है। इसके अलावा इसमें कुछ अन्य छोटी-छोटी
प्रक्रिया भी होती है। इनमें से कुछ प्रमुख निम्नलिखित हैं-
(1)- नाम पद चिह्नन :- व्याकरण में
प्राप्त ‘व्यक्तिवाचक संज्ञाओं’ जैसे- राम, मोहन आदि को प्राकृतिक भाषा संसाधन
प्रणालियों के विकास के क्षेत्र में इन्हें नाम पद कहा जाता है। संसाधन की
प्रक्रिया के दौरान इनका अलग से संज्ञान किया जाता है। शब्द-भेद टैगिंग के दौरान
इनका भी चिह्नन किया जाता है।
(2)- दिनांक
पद चिह्नन :-
दिनांक पदों की संरचना अन्य से भिन्न होती है।
अतः दिनांक संरचनाओं के स्वरूप के आधार पर उसे अलग से चिन्हित करने का कार्य भी
शब्द-भेद टैगिंग के दौरान किया जाता है। जैसे- dd/mm/yy और dd/mm/yyyy आदि।
(3)- बहुशब्दीय
अभिव्यक्ति संज्ञान :-
प्राकृतिक भाषा संसाधन के दौरान आयी हुई एक नई
संकल्पना बहुशब्दीय अभिव्यक्ति है। जब एक से अधिक शब्द एक
साथ रहते हुए एक ही अर्थ का प्रतिनिधित्व करते हों और अलग-अलग आने पर अलग-अलग अर्थों का, तो ऐसे शब्द-युग्म बहुशब्दीय अभिव्यक्ति के अंतर्गत
आते हैं। और इनकी पहचान आवश्यक हो जाती है। यदि इनकी पहचान नहीं होगी और यदि किसी
प्रणाली द्वारा उन्हें अलग-अलग समझ लिया जाएगा तो आगे जो भी प्रक्रिया होगी उसमें
शब्दों के मेल से प्राप्त होने वाला मूल अर्थ प्राप्त नहीं हो सकेगा। अतः इसके बाद
जो भी आउटपुट प्राप्त होगा वह वास्तविक परिणाम से भिन्न होगा। जैसे-
गोरखपाण्डेय छात्रावास, गोपालपुर, चंदन यादव आदि में प्रत्येक शब्द-युग्मों द्वारा
प्राप्त अर्थ उसमें आए शब्दों के अलग-अलग अर्थों को जोड़कर बनाए गए अर्थों से
भिन्न है। अतः शब्द-भेद टैगिंग के दौरान इनके शब्दभेद का भी संज्ञान आवश्यक हो
जाता है।
(4)- मुद्रा चिह्नन :-
विभिन्न देशों की मुद्राओं की रूप रचना एवं
बनावट भिन्न होती है। अतः उन देशों की मुद्राओं और उनसे संबंधित चिन्हों की पहचान
के लिए यह कार्य शब्द-भेद टैगिंग के दौरान किया जाता है।
(5)- विसंदिग्धीकरण :-
सभी भाषाओं का निर्माण प्राकृतिक रूप
से हुआ है इसलिए सभी भाषाएँ जटिल होती हैं। इसमें एक ही शब्द प्रयोग की स्थिति के
आधार पर कई प्रकार्यात्मक भूमिकाओं का निर्वहन करता है। इसी स्थिति में कुछ शब्दों
की संरचनात्मक कोटि और अर्थ के निर्धारण में संदिग्धता होने पर विसंदिग्धिकरण से
संबंधित टूल का भी प्रयोग किया जाता है।
(6)- पदबंध
चिन्हन:-
पद एवं पदों का विस्तार पदबंध कहलाता
है। किसी वाक्य में आए हुए पदबंधों को अलग-अलग चिन्हित करने की प्रक्रिया पदबंध
चिन्हन है। पदबंध एक शब्द का भी हो सकता है और एक से अधिक शब्दों का भी हो सकता है
यह गतिक संरचना है। पदबंधों की अलग-अलग पहचान के लिए पदबंध रचना नियमों की
आवश्यकता होती है। वाक्य में पदबंधों की पहचान के लिए कोई चिन्हक नहीं आता और न ही
पदों की संख्या के आधार पर उन्हें अलग-अलग पहचाना जा सकता है। हिंदी में परसर्ग,
पदबंध के पूरा होने के सूचक हैं किंतु सभी वाक्यों में कर्ता और कर्म के साथ
परसर्गों का प्रयोग नहीं होता इसलिए अन्य पदबंध रचना नियम भी लगाने पड़ते हैं।

संदर्भ :Ø धनजी प्रसाद:- भाषा विज्ञान का सैद्धांतिक अनुप्रयुक्त एवं तकनीकी पक्ष
Ø https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html
Ø https://lgandlt.blogspot.in/2016/11/blog-post.html?m=0

No comments:
Post a Comment